欢迎来到上海交通大学智能媒体组 (MediaX@SJTU)
MediaX 隶属于 上海交通大学未来媒体网络协同创新中心, 专注于 计算机视觉、机器学习 与 生成式智能媒体 交叉领域的前沿研究。 我们致力于推动多模态媒体(2D/3D/4D)在生成、修复与增强、重建与压缩、以及质量评价等方向的发展。 我们的使命是构建能够理解、建模和操控复杂人类中心视觉内容的智能系统, 以实现高质量、高效率的下一代智能媒体内容生产。
🎯 研究方向
媒体感知与质量评价
构建面向UGC、PGC和AIGC内容的多维度智能质量评价体系。(F-Bench、FineVQ等)
视频修复与生成
高质量视频增强、可控生成与编辑,支持4K/8K分辨率。(MoA-VR、StoryGen、Dr2等)
3D/4D重建与生成
基于3D高斯建模与生成式AI,实现沉浸式动态场景的高效表示与压缩。(4DGCPro、4DGC、VARFVV等)
智能媒体创作平台
构建协同、多智能体驱动的自动化与交互式媒体生产系统。(央视4K/8K超高清媒体智能增强制作平台)
📢 加入我们
我们长期欢迎 博士研究生、硕士研究生、本科科研助理 加入团队。
如果你对智能媒体与生成式AI充满热情,欢迎将 个人简历与成绩单 发送至:
mediax@sjtu.edu.cn
🔥 News:
Publications
|
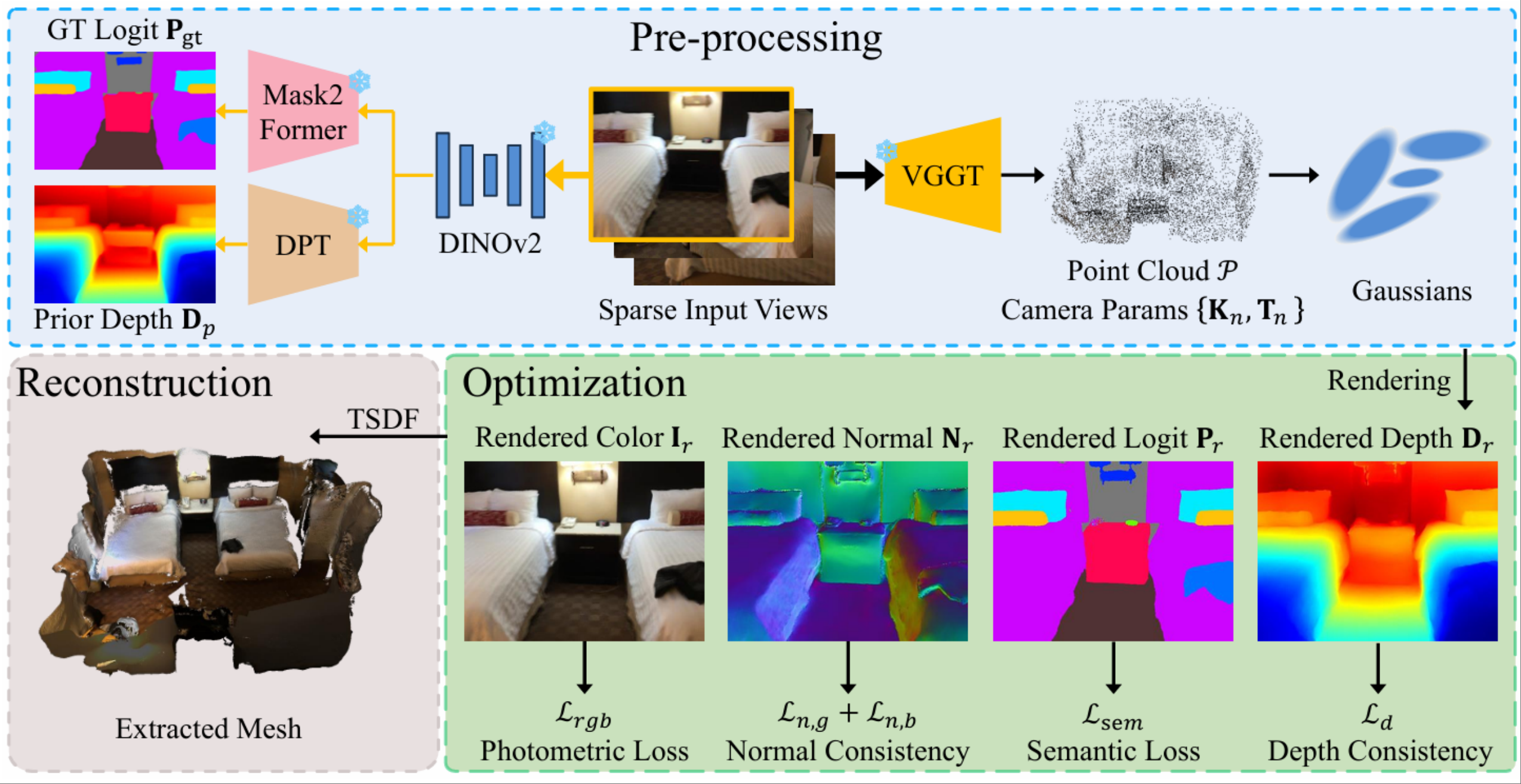
[VCIP'2025] AlignGS: Aligning Geometry and Semantics for Robust Indoor Reconstruction from Sparse Views (Best Paper Award).Yijie Gao, Houqiang Zhong, Tianchi Zhu, Zhengxue Cheng, Qiang Hu, Li Song IEEE Visual Communications and Image Processing (VCIP) 2025. |
|
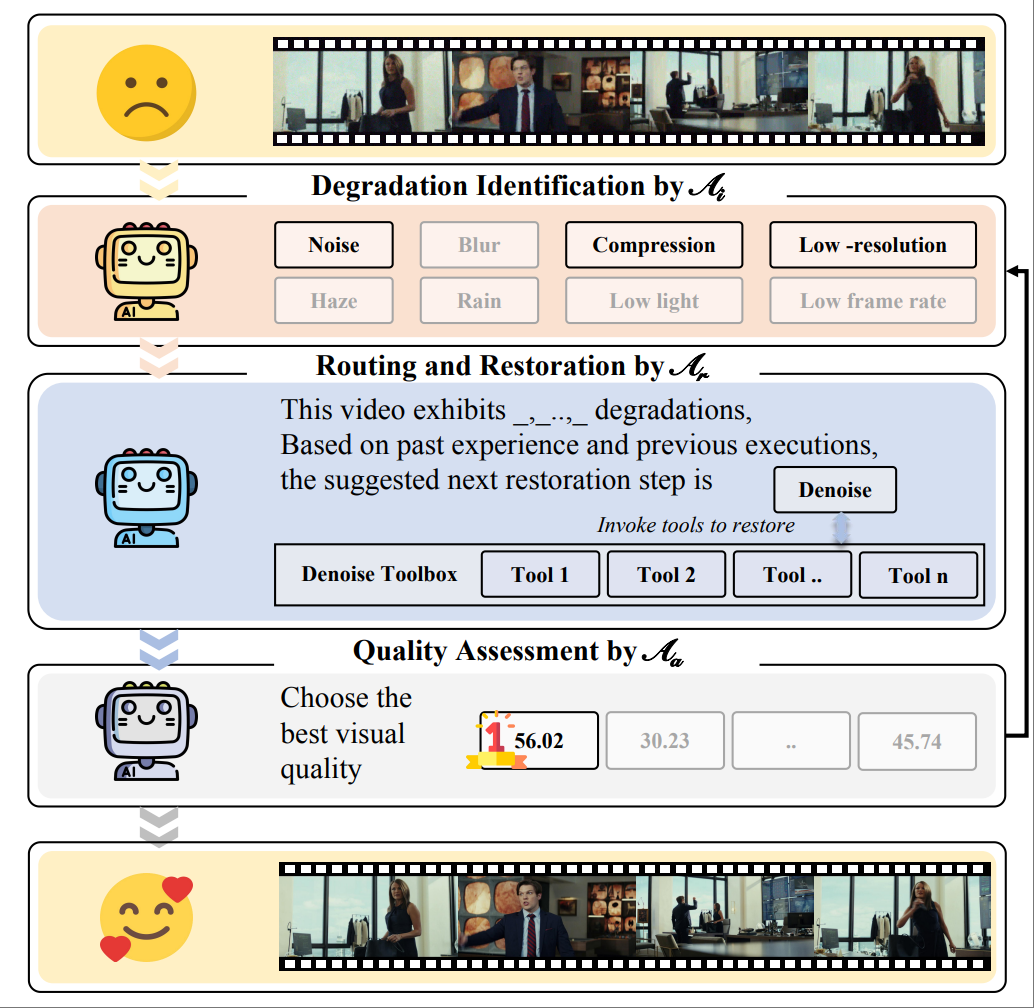
[JSTSP'2025] MoA-VR: A Mixture-of-Agents System Towards All-in-One Video RestorationLu Liu, Chunlei Cai, Shaocheng Shen, Jianfeng Liang, Weimin Ouyang, Tianxiao Ye, Jian Mao, Huiyu Duan, Jiangchao Yao, Xiaoyun Zhang, Qiang Hu, Guangtao Zhai IEEE Journal of Selected Topics in Signal Processing (JSTSP), 2025. |
|
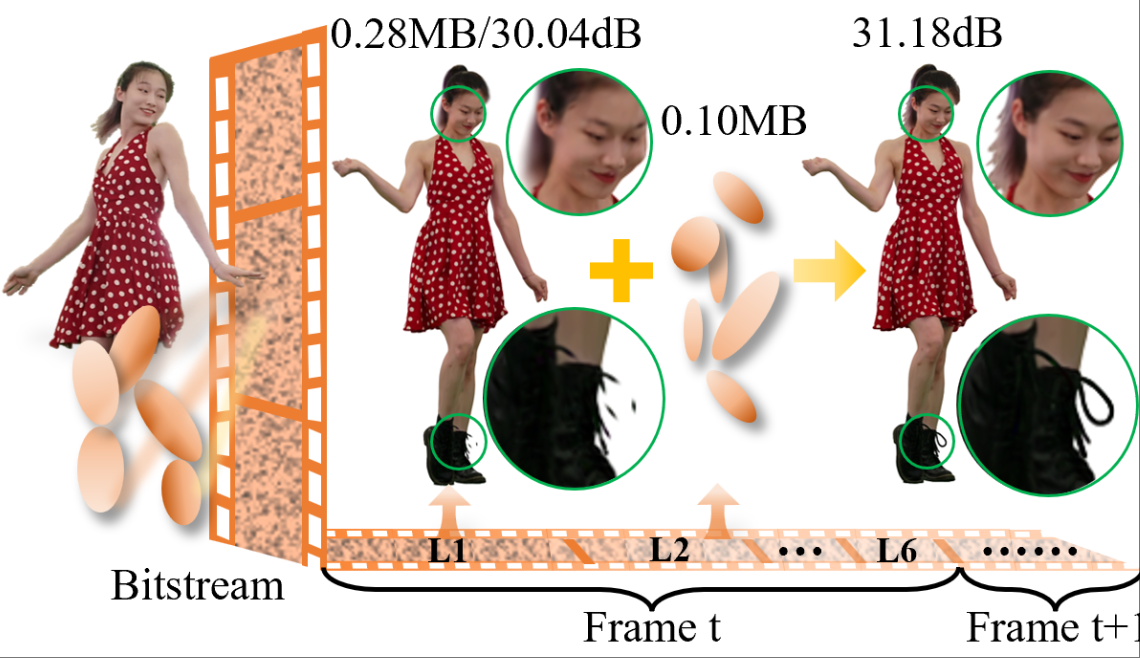
[NeurIPS'2025] 4DGCPro: Efficient Hierarchical 4D Gaussian Compression for Progressive Volumetric Video StreamingZihan Zheng, Zhenlong Wu, Houqiang Zhong, Yuan Tian, Ning Cao, Lan Xu, Jiangchao Yao, Xiaoyun Zhang, Qiang Hu, Wenjun Zhang The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025. |
|
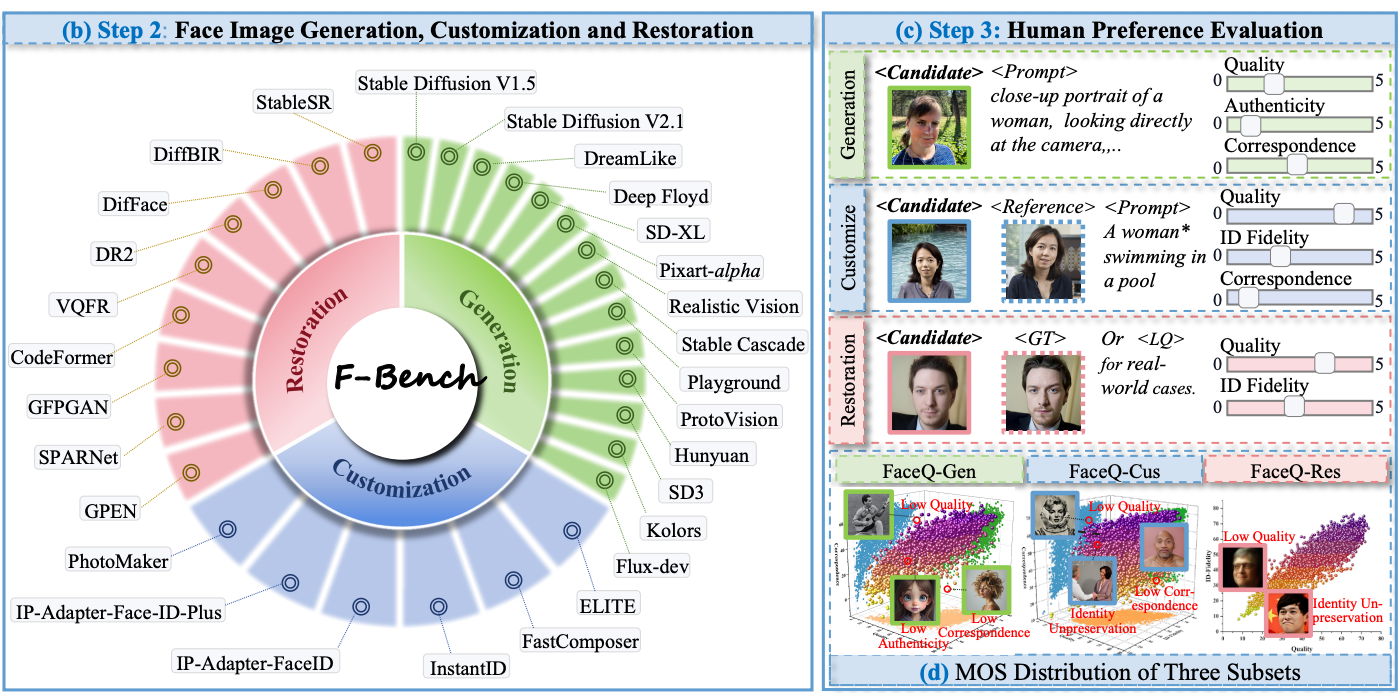
[ICCV'2025] F-Bench: Rethinking Human Preference Evaluation Metrics for Benchmarking Face Generation, Customization, and RestorationLu Liu, Huiyu Duan, Qiang Hu, Liu Yang, Chunlei Cai, Tianxiao Ye, Huayu Liu, Xiaoyun Zhang, Guangtao Zhai IEEE/CVF International Conference on Computer Vision (ICCV), 2025. |
|
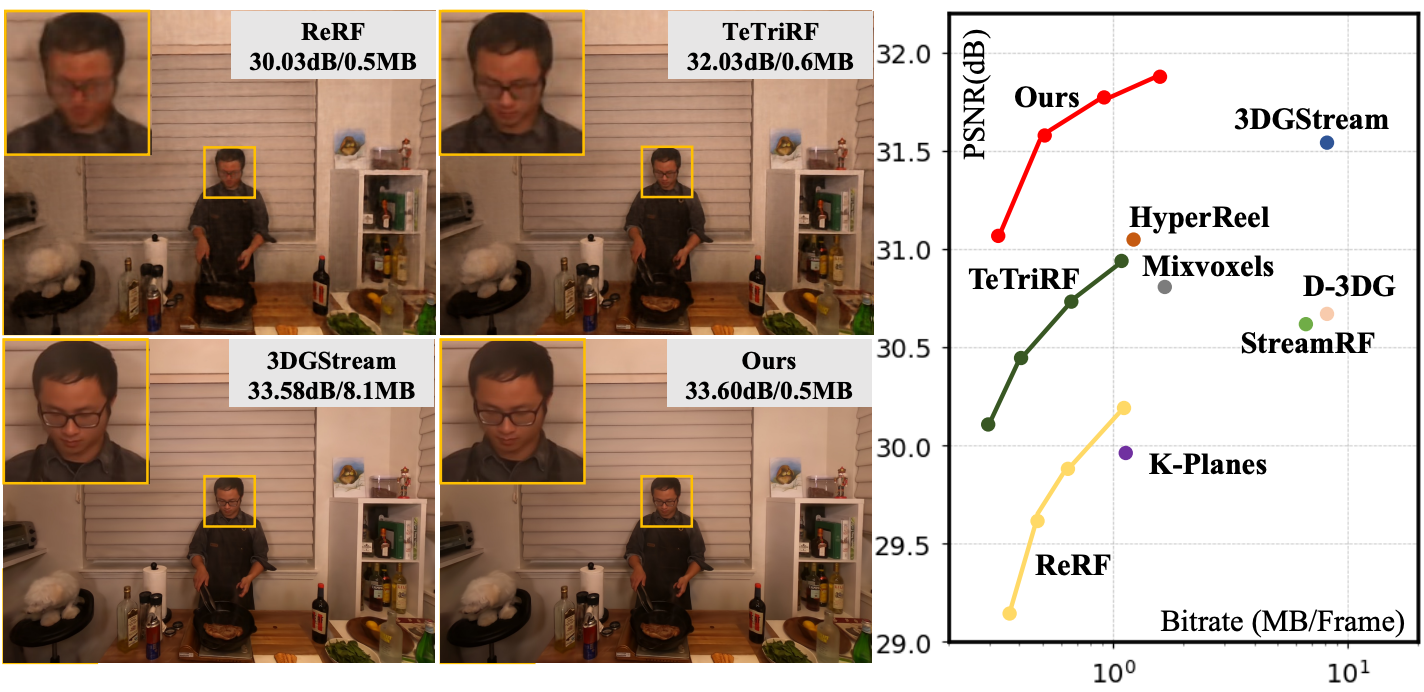
[CVPR'2025]4DGC: Rate-Aware 4D Gaussian Compression for Efficient Streamable Free-Viewpoint VideoQiang Hu, Zihan Zheng, Houqiang Zhong, Sihua Fu, Li Song, Xiaoyun Zhang, Guangtao Zhai, Yanfeng Wang. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. |
|
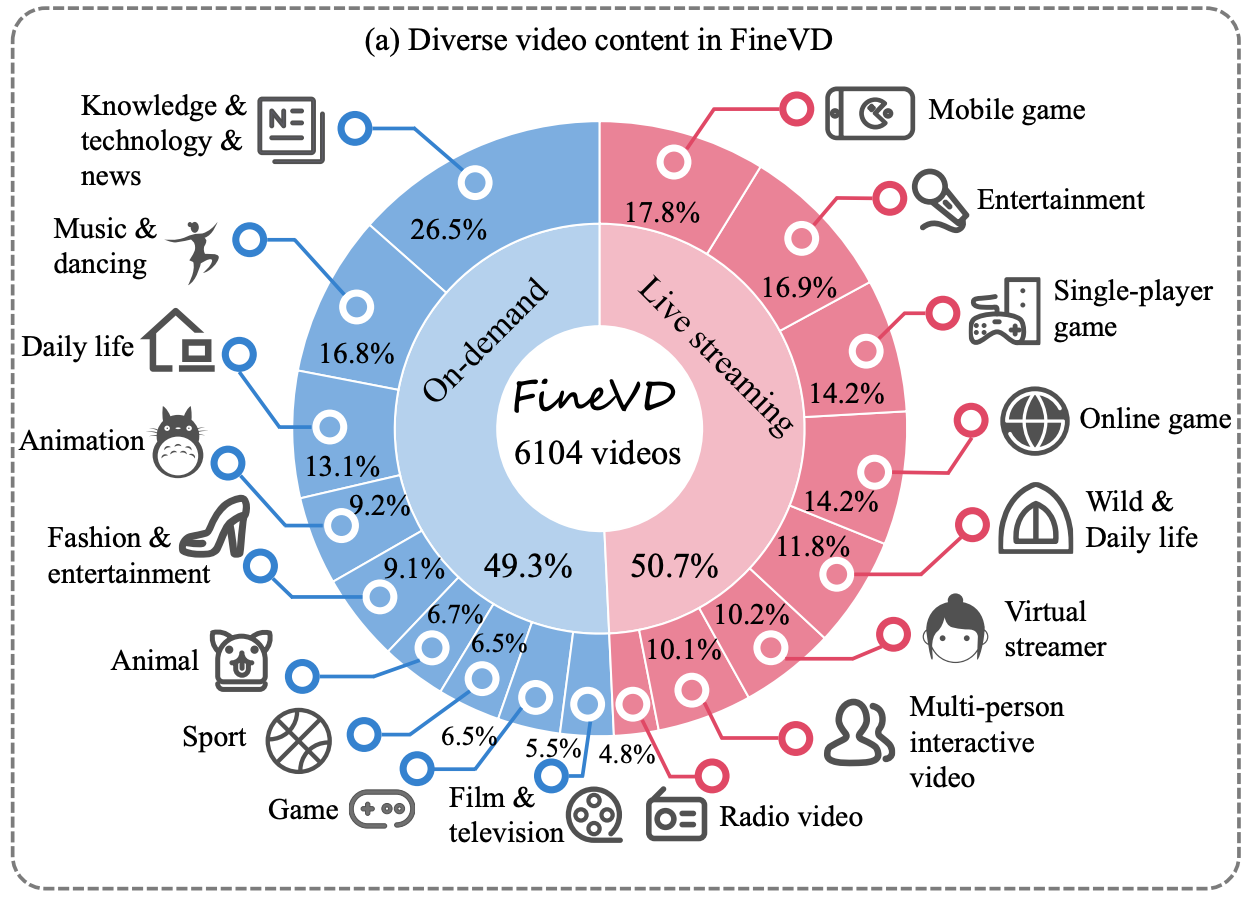
[CVPR'2025] FineVQ: Fine-Grained User Generated Content Video Quality AssessmentHuiyu Duan, Qiang Hu, Wang Jiarui, Liu Yang, Zitong Xu, Lu Liu, Xiongkuo Min, Chunlei Cai, Tianxiao Ye, Xiaoyun Zhang, Guangtao Zhai IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. |
|
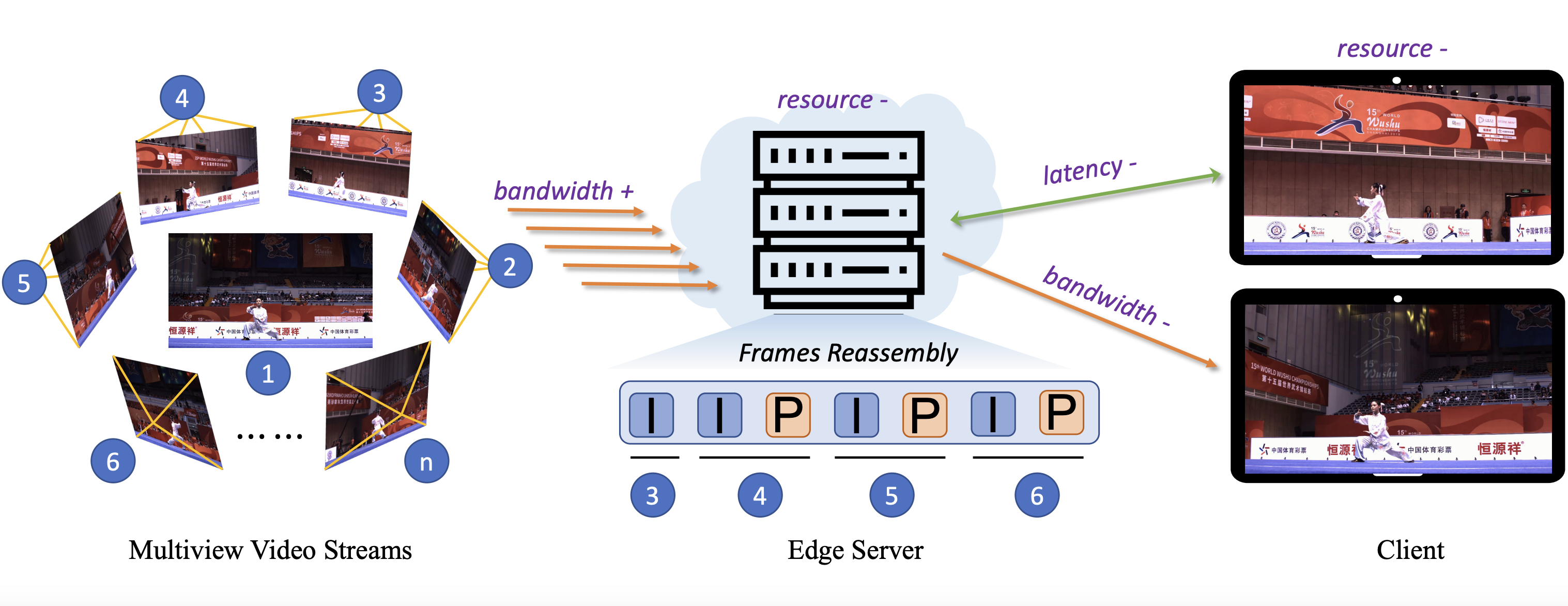
[JSAC'2025]VARFVV: View-Adaptive Real-Time Interactive Free-View Video Streaming with Edge ComputingQiang Hu, Qihan He, Houqiang Zhong, GuoLu, Xiaoyun Zhang,Guangtao Zhai,Yanfeng Wang IEEE Journal on Selected Areas in Communications (JSAC), 2025. |
|
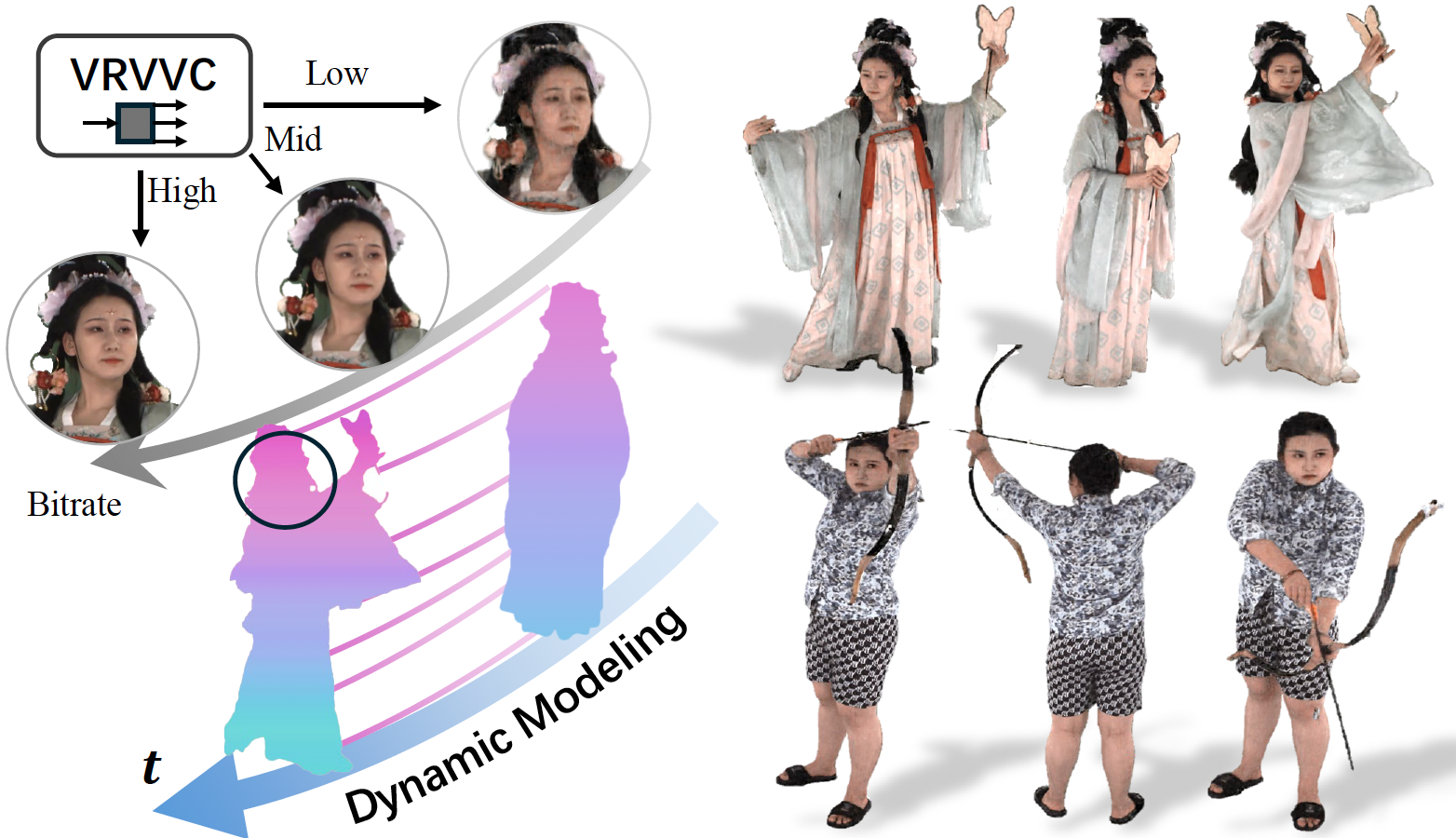
[AAAI'2025] VRVVC: Variable-Rate NeRF-Based Volumetric Video CompressionQiang Hu,Houqiang Zhong,Zihan Zheng,Xiaoyun Zhang,Zhengxue Cheng,Li Song,Guangtao Zhai,Yanfeng Wang The Association for the Advancement of Artificial Intelligence (AAAI), 2025. |
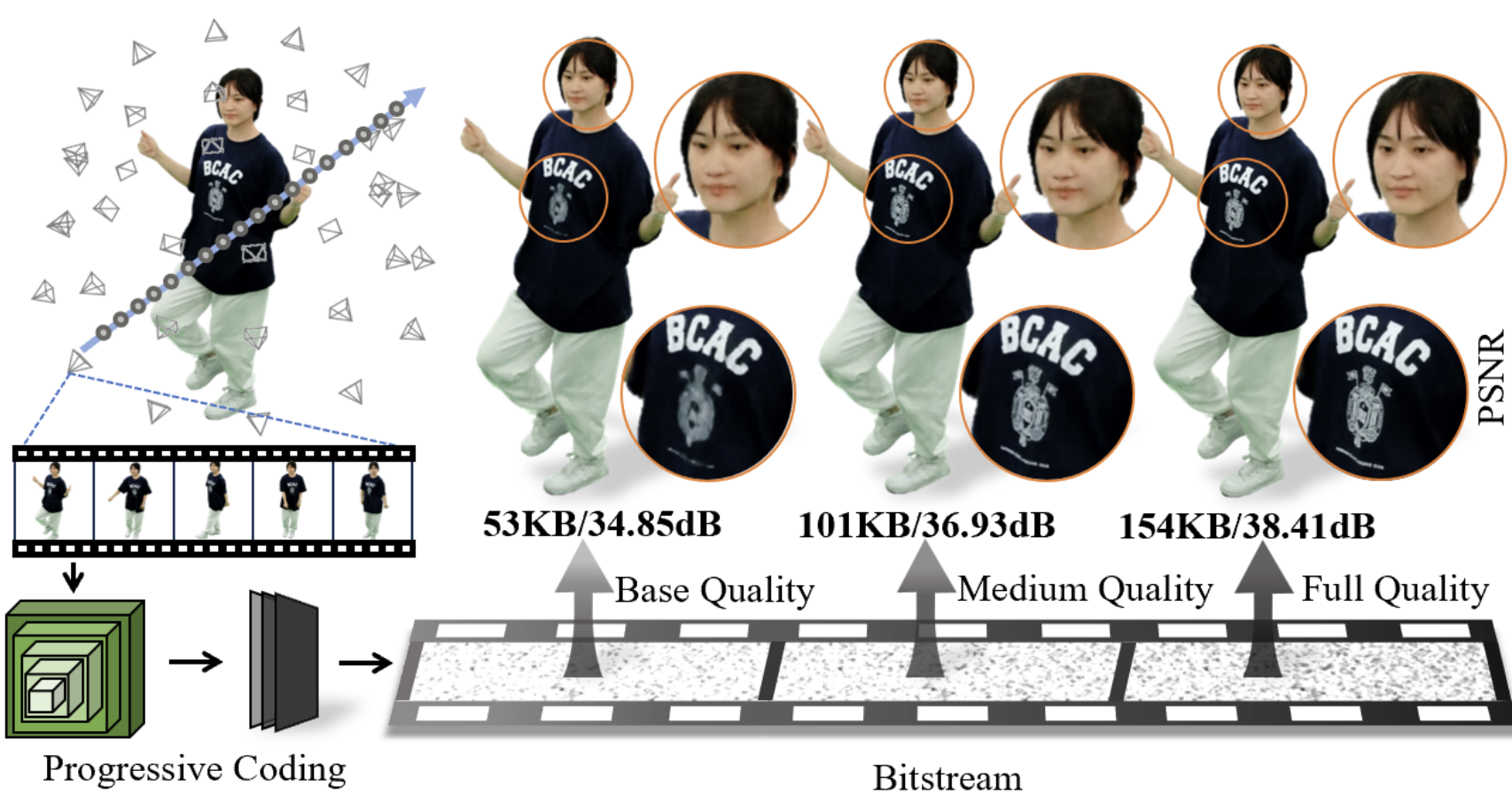
|
[MM'2024] HPC: Hierarchical Progressive Coding Framework for Volumetric VideoZihan Zheng, Houqiang Zhong, Qiang Hu, Xiaoyun Zhang, Li Song, Ya Zhang, Yanfeng Wang Proceedings of the ACM International Conference on Multimedia(MM), 2024. |

|
[CVPR'2024] Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion ModelsChang Liu, Haoning Wu, Yujie Zhong, Xiaoyun Zhang, Yanfeng Wang, Weidi Xie IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. |